
I want to present a re-analysis of the raw data from two studies that investigated whether physical cleanliness reduces the severity of moral judgments – from the original study (n = 40; Schnall, Benton, & Harvey, 2008), and from a direct replication (n = 208, Johnson, Cheung, & Donnellan, 2014). Both data sets are provided on the Open Science Framework. All of my analyses are based on the composite measure as dependent variable.
This re-analsis follows previous analyses by Tal Yarkoni, Yoel Inbar, and R. Chris Fraley, and is focused on one question: What can we learn from the data when we apply modern (i.e., Bayesian and robust) statistical approaches?
The complete and reproducible R code for these analyses is at the end of the post.
Disclaimer 1: This analysis assumes that the studies from which data came from were internally valid. Of course the garbage-in-garbage-out principle holds. But as the original author reviewed the experimental material of the replication study and gave her OK, I assume that the relication data is as valid as the original data.
Disclaimer 2: I am not going to talk about tone, civility, or bullying here. Although these are important issues, a lot has been already written about it, including apologies from one side of the debate (not from the other, yet), etc. For nice overviews over the debate, see for example a blog post by , and the summary provided by Tal Yarkoni). I am completely unemotional about these data. False positives do exists, I am sure I had my share of them, and replication is a key element of science. I do not suspect anybody of anything – I just look at the data.
That being said, let’s get to business:
Bayes factor analysis
The BF is a continuous measure of evidence for H0 or for H1, and quantifies, “how much more likely is H1 compared to H0″. Typically, a BF of at least 3 is requested to speak of evidence (i.e., the H1 should be at least 3 times more likely than the H0 to speak of evidence for an effect). For an introduction to Bayes factors see here, here, or here.
Using the BayesFactor package, it is simple to compute a Bayes factor (BF) for the group comparison. In the original study, the Bayes factor against the H0,  , is 1.08. That means, data are 1.08 times more likely under the H1 (“there is an effect”) than under the H0 (“There is no effect”). As the BF is virtually 1, data occurred equally likely under both hypotheses.
, is 1.08. That means, data are 1.08 times more likely under the H1 (“there is an effect”) than under the H0 (“There is no effect”). As the BF is virtually 1, data occurred equally likely under both hypotheses.
What researchers actually are interested in is not p(Data | Hypothesis), but rather p(Hypothesis | Data). Using Bayes’ theorem, the former can be transformed into the latter by assuming prior probabilities for the hypotheses. The BF then tells one how to update one’s prior probabilities after having seen the data. Given a BF very close to 1, one does not have to update his or her priors. If one holds, for example, equal priors (p(H1) = p(H0) = .5), these probabilities do not change after having seen the data of the original study. With these data, it is not possible to decide between H0 and H1, and being so close to 1, this BF is not even “anectdotal evidence” for H1 (although the original study was just skirting the boundary of significance, p = .06).
For the replication data, the situation looks different. The Bayes factor here is 0.11. That means, H0 is (1 / 0.11) = 9 times more likely than H1. A of 0.11 would be labelled “moderate to strong evidence” for H0. If you had equals priors before, you should update your belief for H1 to 10% and for H0 to 90% (Berger, 2006).
To summarize, neither the original nor the replication study show evidence for H1. In contrast, the replication study even shows quite strong evidence for H0.
A more detailed look at the data using robust statistics
Parametric tests, like the ANOVA employed in the original and the replication study, rest on assumptions. Unfortunately, these assumptions are very rarely met (Micceri, 1989), and ANOVA etc. are not as robust against these violations as many textbooks suggest (Erceg-Hurn & Mirosevic, 2008). Fortunately, over the last 30 years robust statistical methods have been developed that do not rest on such strict assumptions.
In the presence of violations and outliers, these robust methods have much lower Type I error rates and/or higher power than classical tests. Furthermore, a key advantage of these methods is that they are designed in a way that they are equally efficient compared to classical methods, even if the assumptions are not violated. In a nutshell, when using robust methods, there nothing to lose, but a lot to gain.
Rand Wilcox pioneered in developing many robust methods (see, for example, this blog post by him), and the methods are implemented in the WRS package for R (Wilcox & Schönbrodt, 2014).
Comparing the central tendency of two groups
A robust alternative to the independent group t test would be to compare the trimmed means via percentile bootstrap. This method is robust against outliers and does not rest on parametric assumptions. Here we find a p value of .106 for the original study and p = .94 for the replication study. Hence, the same picture: No evidence against the H0.
Comparing other-than-central tendencies between two groups, aka.: Comparing extreme quantiles between groups
When comparing data from two groups, approximately 99.6% of all psychological research compares the central tendency (that is a subjective estimate). In some cases, however, it would be sensible to compare other parts of the distributions.For example, an intervention could have effects only on slow reaction times (RT), but not on fast or medium RTs. Similarly, priming could have an effect only on very high responses, but not on low and average responses. Measures of central tendency might obscure or miss this pattern.
And indeed, descriptively there (only) seems to be a priming effect in the “extremely wrong pole” (large numbers on the x axis) of the original study (i.e., the black density line is higher than the red on at “7” and “8” ratings):
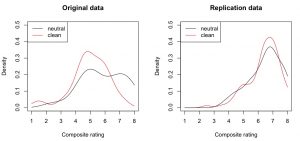
This visual difference can be tested. Here, I employed the [cci]qcomhd[/cci] function from the WRS package (Wilcox, Erceg-Hurn, Clark, & Carlson, 2013). This method looks whether two samples differ in several quantiles (not only the central tendency). For an introduction to this method, see this blog post.
Here’s the result when comparing the 10th, 30th, 50th, 70th, and 90th quantile:
[cc lang=”rsplus” escaped=”true”]
q n1 n2 est.1 est.2 est.1_minus_est.2 ci.low ci.up p_crit p.value signif
1 0.1 20 20 3.86 3.15 0.712 -1.077 2.41 0.0500 0.457 NO
2 0.3 20 20 4.92 4.51 0.410 -0.341 1.39 0.0250 0.265 NO
3 0.5 20 20 5.76 5.03 0.721 -0.285 1.87 0.0167 0.197 NO
4 0.7 20 20 6.86 5.70 1.167 0.023 2.05 0.0125 0.047 NO
5 0.9 20 20 7.65 6.49 1.163 0.368 1.80 0.0100 0.008 YES
[/cc]
(Please note: Estimating 5 quantiles from 20 data points is not quite the epitome of precision. So treat this analysis with caution.)
As multiple comparison are made, the Benjamini-Hochberg-correction for the p value is applied. This correction gives new critical p values (column [cci]p_crit[/cci]) to which the actual p values (column [cci]p.value[/cci]) have to be compared. One quantile survives the correction: the 90th quantile. That means that there are fewer extreme answers in the cleanliness priming group than in the control group. This finding, of course, is purely exploratory, and as any other exploratory finding it awaits cross-validation in a fresh data set. Luckily, we have the replication data set! Let’s see whether we can replicate this effect.
The answer is: no. Not even a tendency:
[cc lang=”rsplus” escaped=”true”]
q n1 n2 est.1 est.2 est.1_minus_est.2 ci.low ci.up p_crit p.value signif
1 0.1 102 106 4.75 4.88 -0.1309 -0.705 0.492 0.0125 0.676 NO
2 0.3 102 106 6.00 6.12 -0.1152 -0.571 0.386 0.0250 0.699 NO
3 0.5 102 106 6.67 6.61 0.0577 -0.267 0.349 0.0500 0.737 NO
4 0.7 102 106 7.11 7.05 0.0565 -0.213 0.411 0.0167 0.699 NO
5 0.9 102 106 7.84 7.73 0.1111 -0.246 0.431 0.0100 0.549 NO
[/cc]
Here’s a plot of the results:

Overall summary
From the Bayes factor analysis, both the original and the replication study do not show evidence for the H1. The replication study actually shows moderate to strong evidence for the H0.
If anything, the original study shows some exploratory evidence that only the high end of the answer distribution (around the 90th quantile) is reduced by the cleanliness priming – not the central tendency. If one wants to interpret this effect, it would translate to: “Cleanliness primes reduce extreme morality judgements (but not average or low judgements)”. This exploratory effect, however, could not be cross-validated in the better powered replication study.
Outlook
Recently, Silberzahn, Uhlmann, Martin, and Nosek proposed “crowdstorming a data set”, in cases where a complex data set calls for different analytical approaches. Now, a simple two group experimental design, usually analyzed with a t test, doesn’t seem to have too much complexity – still it is interesting how different analytical approaches highlight different aspects of the data set. And it is also interesting to see that the majority of diverse approaches comes to the same conclusion: From this data base, we can conclude that we cannot conclude that the H0 is wrong (This sentence, a hommage to Cohen, 1990, was for my Frequentist friends ;-)).
And, thanks to Bayesian approaches, we can say (and even understand): There is strong evidence that the H0 is true. Very likely, there is no priming effect in this paradigm.
PS: Celebrate open science. Without open data, all of this would not be possible.
[cc lang=”rsplus” escaped=”true” collapse=”true”]
## (c) 2014 Felix Schönbrodt
## https://www.nicebread.de
##
## This is a reanalysis of raw data from
## – Schnall, S., Benton, J., & Harvey, S. (2008). With a clean conscience cleanliness reduces the severity of moral judgments. Psychological Science, 19(12), 1219-1222.
## – Johnson, D. J., Cheung, F., & Donnellan, M. B. (2014). Does Cleanliness Influence Moral Judgments? A Direct Replication of Schnall, Benton, and Harvey (2008). Social Psychology, 45, 209-215.
## ======================================================================
## Read raw data, provided on Open Science Framework
# – https://osf.io/4cs3k/
# – https://osf.io/yubaf/
## ======================================================================
library(foreign)
dat1 <- read.spss(“raw/Schnall_Benton__Harvey_2008_Study_1_Priming.sav”, to.data.frame=TRUE) dat2 <- read.spss(“raw/Exp1_Data.sav”, to.data.frame=TRUE) dat2 <- dat2[dat2[, “filter_.”] == “Selected”, ] dat2$condition <- factor(dat2$Condition, labels=c(“neutral priming”, “clean priming”)) table(dat2$condition) # build composite scores from the 6 vignettes: dat1$DV <- rowMeans(dat1[, c(“dog”, “trolley”, “wallet”, “plane”, “resume”, “kitten”)]) dat2$DV <- rowMeans(dat2[, c(“Dog”, “Trolley”, “Wallet”, “Plane”, “Resume”, “Kitten”)]) # define shortcuts for DV in each condition neutral <- dat1$DV[dat1$condition == “neutral priming”] clean <- dat1$DV[dat1$condition == “clean priming”] neutral2 <- dat2$DV[dat2$condition == “neutral priming”] clean2 <- dat2$DV[dat2$condition == “clean priming”] ## ====================================================================== ## Original analyses with t-tests/ ANOVA ## ====================================================================== # ——————————————————————— # Original study: # Some descriptives … mean(neutral) sd(neutral) mean(clean) sd(clean) # Run the ANOVA from Schnall et al. (2008) a1 <- aov(DV ~ condition, dat1) summary(a1) # p = .0644 # –> everything as in original publication
# ———————————————————————
# Replication study
mean(neutral2)
sd(neutral2)
mean(clean2)
sd(clean2)
a2 <- aov(DV ~ condition, dat2) summary(a2) # p = .947 # –> everything as in replication report
## ======================================================================
## Bayes factor analyses
## ======================================================================
library(BayesFactor)
ttestBF(neutral, clean, rscale=1) # BF_10 = 1.08
ttestBF(neutral2, clean2, rscale=1) # BF_10 = 0.11
## ======================================================================
## Robust statistics
## ======================================================================
library(WRS)
# ———————————————————————
# robust tests: group difference of central tendency
# percentile bootstrap for comparing measures of location:
# 20% trimmed mean
trimpb2(neutral, clean) # p = 0.106 ; CI: [-0.17; +1.67]
trimpb2(neutral2, clean2) # p = 0.9375; CI: [-0.30; +0.33]
# median
medpb2(neutral, clean) # p = 0.3265; CI: [-0.50; +2.08]
medpb2(neutral2, clean2) # p = 0.7355; CI: [-0.33; +0.33]
# ———————————————————————
# Comparing other quantiles (not only the central tendency)
# plot of densities
par(mfcol=c(1, 2))
plot(density(clean, from=1, to=8), ylim=c(0, 0.5), col=”red”, main=”Original data”, xlab=”Composite rating”)
lines(density(neutral, from=1, to=8), col=”black”)
legend(“topleft”, col=c(“black”, “red”), lty=”solid”, legend=c(“neutral”, “clean”))
plot(density(clean2, from=1, to=8), ylim=c(0, 0.5), col=”red”, main=”Replication data”, xlab=”Composite rating”)
lines(density(neutral2, from=1, to=8), col=”black”)
legend(“topleft”, col=c(“black”, “red”), lty=”solid”, legend=c(“neutral”, “clean”))
# Compare quantiles of original study …
par(mfcol=c(1, 2))
qcomhd(neutral, clean, q=seq(.1, .9, by=.2), xlab=”Original: Neutral Priming”, ylab=”Neutral – Clean”)
abline(h=0, lty=”dotted”)
# Compare quantiles of replication study
qcomhd(neutral2, clean2, q=seq(.1, .9, by=.2), xlab=”Replication: Neutral Priming”, ylab=”Neutral – Clean”)
abline(h=0, lty=”dotted”)
[/cc]
References
Berger, J. O. (2006). Bayes factors. In S. Kotz, N. Balakrishnan, C. Read, B. Vidakovic, & N. L. Johnson (Eds.), Encyclopedia of Statistical Sciences, vol. 1 (2nd ed.) (pp. 378–386). Hoboken, NJ: Wiley.
Erceg-Hurn, D. M., & Mirosevich, V. M. (2008). Modern robust statistical methods: An easy way to maximize the accuracy and power of your research. American Psychologist, 63, 591–601.
Micceri, T. (1989). The unicorn, the normal curve, and other improbable creatures. Psychological Bulletin, 105, 156–166. doi:10.1037/0033-2909.105.1.156
Schnall, S., Benton, J., & Harvey, S. (2008). With a clean conscience cleanliness reduces the severity of moral judgments. Psychological Science, 19(12), 1219–1222.
Wilcox, R. R., Erceg-Hurn, D. M., Clark, F., & Carlson, M. (2013). Comparing two independent groups via the lower and upper quantiles. Journal of Statistical Computation and Simulation, 1–9. doi:10.1080/00949655.2012.754026
Wilcox, R.R., & Schönbrodt, F.D. (2014). The WRS package for robust statistics in R (version 0.25.2). Retrieved from https://github.com/nicebread/WRS
Thanks for conducting this analysis. A couple comments:
1. I would assume that this manipulation has some effects, though they could be very small. So my prior is a continuous distribution over the average treatment effect (ATE). How does this analysis work then?
2. So many digits! options(digits=3) is your friend.
3. You compare other quantities besides means. With a mean we have E[Y1 – Y0] = E[Y1] – E[Y0]. That is, the difference in means is the mean difference. Not so with other many other quantities. Note that, e.g., median treatment effects are not identified.
4. Not sure I understand the motivation to winsorize or trim the means. These are quite small samples. And the domain is so small — each observation has really limited potential leverage. 20% is a lot of trimming!
Dean, thanks for your comments!
ad 1: Do you refer here to the Bayes factor analysis? The BF analysis actually assumes a continuous prior for the effect size under the H1 that has the form of a Cauchy distribution (for details, see this blog post by Richard Morey). The rscale parameter in the ttestBF function controls the width of this prior. If you assume a priori that the effect is very small, you can choose a smaller rscale, such as .7 or .5. This will increase your BF a bit towards the H1, but not substantially.
ad 2: Good point! I updated the output, looks much better now.
ad 3: Not so sure what you mean here …
ad 4: Trimming is done after the bootstrapping – i.e., an observation has the chance to enter in each of 2000 bootstrap samples, so it’s not always the same part of the sample that is trimmed away. 20% is somewhat a standard choice, although Rosenberger and Gasko (1983) even suggest to use 25% trimming in small samples! (The more you trim, the closer gets the trimmed mean to the median). For winsorizing, Wilcox suggests a minimum of 15 observations. For more details, see Wilcox & Keselman (2003).
Thanks for your reply!
1. Ah, I guess what I mean is that it is informative about evidence against H0, but I don’t believe H0 at all (my continuous prior puts 0 probability on any point).
2. Neat!
3. This is just the point that not all features of the treatment effect distribution are identified. This is discussed in a lot of the standard papers on causal inference.
4. The usual motivation for trimmed means etc is robustness to outliers. ie limiting the influence of a single observation at Inf. This can also reduce variance. But here things are quite well bounded. And the distribution is so discrete, that the trimming point is within a big mass.
ad 4: OK, now I see your point! Indeed, bounded data often reduces the occurence of outliers. But trimmed means also help with skewed distributions, and there seems to be some skewness in the data! Probably the merits of trimmed means are not very pronounced with these kind of data, but I think the approach doesn’t hurt either. And, as RR Wilcox points out in his comment, trimming can be advantageous in small samples as well.
Dean and Felix,
There are various reasons why trimming with a small sample size can be very advantageous. One was touched on by Felix. It is counter
intuitive based on standard training that trimming can result in a smaller standard error and improved power, sometimes substantially so.
But if you look at the correct expression for the standard error, which involves Winsorizing the data, you can get an idea of why this happens.
(About 2 centuries ago, Laplace established that the median can have a smaller standard error than the mean.) Illustrations and a more detailed explanation are given in my 2012 books. Also, theory and simulations indicate that trimming helps reduce problems with skewed distributions in terms of controlling the Type I error probability. Standard methods based on means work fine when dealing with symmetric, light-tailed distributions. But otherwise, even with a large sample size, serious problems can occur in terms of
both Type I errors and power. Again, for a more detailed explanation, see my books.
Thanks for the comments. Is there a paper you might recommend? (ie a way to learn about this short of reading a book)
I use winsorization all the time, but generally with data that takes on many, many unique values and has long (heavy) tails.
I don’t see how you can say thanks to Bayesian approaches we can infer no effect. With my strong prior belief in the effect, I believe it after the data as well. Nor does the multiple comparison adjustment get a Bayesian rationale. It is only a frequentist critique of the reported error probabilities that leads to denying evidence for the taking the effect to have been shown.
I generally agree to your point, and I demonstrated that the BF is used to update your prior probabilities, didn’t I?
On the other hand, your prior belief for H1 would have to be around 91% in order that you still opt for H1 after having seen the data of the replication study.
Assumed that you start with equal priors, p(H1) = p(H0) = 50%, which is a default position for many, then the original study updates your belief for H1 to 52%. Hence, if your prior is somewhat based on prior empirical evidence, it is hard to get to a prior of 91% for H1, especially when you take the effect sizes from the other replication studies into account (https://curatescience.org/schnalletal.html).
In principle agree with your point, and the last two sentences of my post indeed include implicit priors. However, I would still say that under a very broad range of reasonable priors the conclusion would be “There probably is no effect”.
The second analysis, where the quantiles are compared, is a “frequentist-style” analysis, so indeed there’s no direct Bayesian rationale for the adjustment.
It was not my plan to start a philosophical “Frequentist vs. Bayes debate” with that post – actually I used both approaches in order to show some insights that could not be obtained from a run-the-mill t-test that is typically applied to this kind of data.
I think both approaches can be valuables tools that allow to draw valid conclusions. Nonetheless, for my own understanding Bayesian results often are easier to interpret and to communicate than frequentist results.