
Correcting bias in meta-analyses: What not to do (meta-showdown Part 1)
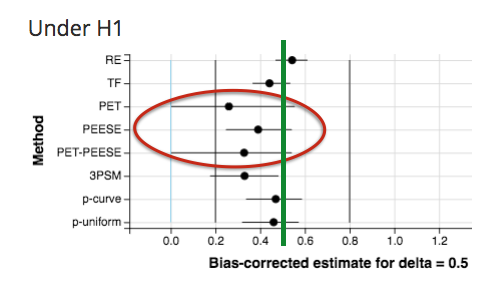
tl;dr: Publication bias and p-hacking can dramatically inflate effect size estimates in meta-analyses. Many methods have been proposed to correct for such bias and to estimate the underlying true effect. In a large simulation study, we studied which methods do Continue Reading …